Example
The following example shows a generic loosely synchronous, iterative
code, using MPI_WIN_FENCE for synchronization. The window at each MPI process
consists of array A, which contains the origin and target buffers of
the
put operations.
...
while (!converged(A)) {
update(A);
MPI_Win_fence(MPI_MODE_NOPRECEDE, win);
for(i=0; i < toneighbors; i++)
MPI_Put(&frombuf[i], 1, fromtype[i], toneighbor[i],
todisp[i], 1, totype[i], win);
MPI_Win_fence((MPI_MODE_NOSTORE | MPI_MODE_NOSUCCEED), win);
}
The same code could be written with get rather than put. Note that,
during the communication phase, each
window is concurrently read (as origin buffer of puts) and written
(as target buffer of puts). This is OK, provided that there is no
overlap between the target buffer of a put and another communication
buffer.
Example
Same generic example, with more computation/communication overlap. We
assume that the update phase is broken into two
subphases: the first,
where the ``boundary,'' which is involved in communication, is updated, and
the second, where the ``core,'' which neither
uses nor provides
communicated data, is updated.
...
while (!converged(A)) {
update_boundary(A);
MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win);
for(i=0; i < fromneighbors; i++)
MPI_Get(&tobuf[i], 1, totype[i], fromneighbor[i],
fromdisp[i], 1, fromtype[i], win);
update_core(A);
MPI_Win_fence(MPI_MODE_NOSUCCEED, win);
}
The get communication can be concurrent with the core update, since
they do not access the same locations, and the local update of the
origin buffer by the get operation can be concurrent with the local update
of the core by the update_core call. In order to get similar
overlap with put communication we would need to use separate windows
for the core and for the boundary.
This is required
because we do not allow local stores to be concurrent with puts
on the same, or on overlapping, windows.
Example
Same code as in Example Examples,
rewritten using post-start-complete-wait.
...
while (!converged(A)) {
update(A);
MPI_Win_post(fromgroup, 0, win);
MPI_Win_start(togroup, 0, win);
for(i=0; i < toneighbors; i++)
MPI_Put(&frombuf[i], 1, fromtype[i], toneighbor[i],
todisp[i], 1, totype[i], win);
MPI_Win_complete(win);
MPI_Win_wait(win);
}
Example
Same example, with post-start-complete-wait, as in Example Examples.
...
while (!converged(A)) {
update_boundary(A);
MPI_Win_post(togroup, MPI_MODE_NOPUT, win);
MPI_Win_start(fromgroup, 0, win);
for(i=0; i < fromneighbors; i++)
MPI_Get(&tobuf[i], 1, totype[i], fromneighbor[i],
fromdisp[i], 1, fromtype[i], win);
update_core(A);
MPI_Win_complete(win);
MPI_Win_wait(win);
}
Example
[Double buffer in RMA]CDouble buffer in RMA@Double buffer in RMAMPI_Barrier,MPI_Win_post,MPI_Win_start,MPI_Get,MPI_Win_complete,MPI_Win_waitA checkerboard, or double buffer communication pattern, that allows
more computation/communication overlap. Array A0 is updated
using values of array A1, and vice versa. We assume that communication is symmetric: if process A gets data from process B, then process B gets data from process A. Window wini consists of array Ai.
...
if (!converged(A0,A1))
MPI_Win_post(neighbors, (MPI_MODE_NOCHECK | MPI_MODE_NOPUT), win0);
MPI_Barrier(comm0);
/* the barrier is needed because the start call inside the
loop uses the nocheck option */
while (!converged(A0, A1)) {
/* communication on A0 and computation on A1 */
update2(A1, A0); /* local update of A1 that depends on A0 (and A1) */
MPI_Win_start(neighbors, MPI_MODE_NOCHECK, win0);
for(i=0; i < fromneighbors; i++)
MPI_Get(&tobuf0[i], 1, totype0[i], neighbor[i],
fromdisp0[i], 1, fromtype0[i], win0);
update1(A1); /* local update of A1 that is
concurrent with communication that updates A0 */
MPI_Win_post(neighbors, (MPI_MODE_NOCHECK | MPI_MODE_NOPUT), win1);
MPI_Win_complete(win0);
MPI_Win_wait(win0);
/* communication on A1 and computation on A0 */
update2(A0, A1); /* local update of A0 that depends on A1 (and A0) */
MPI_Win_start(neighbors, MPI_MODE_NOCHECK, win1);
for(i=0; i < fromneighbors; i++)
MPI_Get(&tobuf1[i], 1, totype1[i], neighbor[i],
fromdisp1[i], 1, fromtype1[i], win1);
update1(A0); /* local update of A0 that depends on A0 only,
concurrent with communication that updates A1 */
if (!converged(A0,A1))
MPI_Win_post(neighbors, (MPI_MODE_NOCHECK | MPI_MODE_NOPUT), win0);
MPI_Win_complete(win1);
MPI_Win_wait(win1);
}
An MPI process posts the local window associated with win0 before it completes RMA accesses to the remote windows associated with win1. When the call to MPI_WIN_WAIT on win1 returns, then all neighbors of the calling MPI process have posted the windows associated with win0. Conversely, when the call to MPI_WIN_WAIT on win0 returns, then all neighbors of the calling MPI process have posted the windows associated with win1. Therefore, the MPI_MODE_NOCHECK option can be used with the calls to MPI_WIN_START.
Put operations can be used, instead of get operations, if the area of array A0 (resp. A1) used by update(A1, A0) (resp. update(A0, A1)) is disjoint from the area modified by the RMA operation. On some systems, a put operation may be more efficient than a get operation, as it requires information exchange only in one direction.
In the next several examples, for conciseness, the expression
![]()
means to perform a get-accumulate operation with the result buffer (given by result_addr in the description of MPI_GET_ACCUMULATE) on the left side of the assignment, in this case, z. This format is also used with MPI_COMPARE_AND_SWAP and MPI_COMM_SIZE. Process B... refers to any process other than A.
Example
The following example implements a naive, nonscalable counting
semaphore. The example demonstrates the use of
MPI_WIN_SYNC to manipulate the public copy of X, as well
as MPI_WIN_FLUSH to complete operations without closing the
access epoch opened with MPI_WIN_LOCK_ALL. To avoid the
rules regarding synchronization of the public and private copies of
windows, MPI_ACCUMULATE and MPI_GET_ACCUMULATE
are used to write to or read from the local public copy.

Example
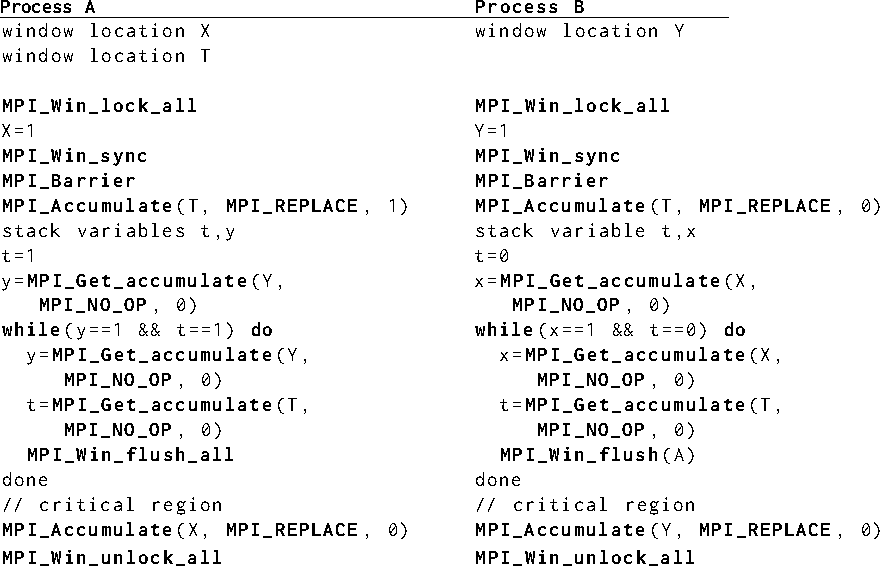
[Critical region with RMA]NeutralCritical region with RMA@Critical region with RMAMPI_Barrier,MPI_Accumulate,MPI_Win_sync,MPI_Get_accumulate,MPI_Win_flush,MPI_Win_flush_allImplementing a critical region between two MPI processes (Peterson's
algorithm). Despite their appearance in the
following example, MPI_WIN_LOCK_ALL and
MPI_WIN_UNLOCK_ALL are not collective calls, but it is
frequently useful to open shared access epochs to all MPI processes from
all other MPI processes in a window. Once the access epochs are
opened, accumulate operations as well as flush and sync
synchronization can be used to read from or write to the
public copy of the window.
Example
Implementing a critical region between multiple MPI processes with compare
and swap. The call to MPI_WIN_SYNC is necessary on
Process A after local initialization of A to guarantee the public copy
has been updated with the initialization value found in the private
copy. It would also be valid to call MPI_ACCUMULATE with
MPI_REPLACE to directly initialize the public copy. A call
to MPI_WIN_FLUSH would be necessary to assure A in the
public copy of Process A had been updated before the barrier.

ExampleThe following example demonstrates the proper synchronization in the
unified memory model when a data transfer is implemented with load and
store accesses in the case of windows in shared memory (instead of using MPI_PUT or
MPI_GET) and the synchronization between MPI processes is performed using
point-to-point communication. The synchronization between MPI processes
must be supplemented with a memory synchronization through calls to
MPI_WIN_SYNC, which act locally as a processor-memory barrier. In
Fortran, if MPI_ASYNC_PROTECTS_NONBLOCKING is
.FALSE.
or the variable X is not declared as ASYNCHRONOUS,
reordering of the accesses to the
variable X must be prevented with MPI_F_SYNC_REG
operations. (No equivalent function is needed in C.)
The variable X is contained within a shared memory window and X corresponds to the same memory location at both processes. The first call to MPI_WIN_SYNC performed by process A ensures completion of the load/store accesses issued by process A. The first call to MPI_WIN_SYNC performed by process B ensures that process A's updates to X are visible to process B. Similarly, the second call to MPI_WIN_SYNC on each process ensures correct ordering of the point-to-point communication and thus that the load/store operations on process B have completed before any subsequent load/store accesses to the variable X in process A.

Example
The following example shows how request-based operations can be used
to overlap communication with computation. Each MPI process fetches,
processes, and writes the result for NSTEPS chunks of data. Instead
of a single buffer, M local buffers are used to allow up to M
communication operations to overlap with computation.
int i, j;
MPI_Win win;
MPI_Request put_req[M] = { MPI_REQUEST_NULL };
MPI_Request get_req;
double *baseptr;
double data[M][N];
MPI_Win_allocate(NSTEPS*N*sizeof(double), sizeof(double), MPI_INFO_NULL,
MPI_COMM_WORLD, &baseptr, &win);
MPI_Win_lock_all(0, win);
for (i = 0; i < NSTEPS; i++) {
if (i<M)
j=i;
else
MPI_Waitany(M, put_req, &j, MPI_STATUS_IGNORE);
MPI_Rget(data[j], N, MPI_DOUBLE, target, i*N, N, MPI_DOUBLE, win,
&get_req);
MPI_Wait(&get_req,MPI_STATUS_IGNORE);
compute(i, data[j], ...);
MPI_Rput(data[j], N, MPI_DOUBLE, target, i*N, N, MPI_DOUBLE, win,
&put_req[j]);
}
MPI_Waitall(M, put_req, MPI_STATUSES_IGNORE);
MPI_Win_unlock_all(win);
Example
The following example constructs a distributed shared linked list using dynamic
windows. Initially process 0 creates the head of the list, attaches it to
the window, and broadcasts the pointer to all MPI processes. All MPI processes then
concurrently append N new elements to the list. When an MPI
process attempts to
attach its element to the tail of the list it may discover that its tail pointer
is stale and it must chase ahead to the new tail before the element can be
attached.
This example requires some modification to
work in an environment where the layout of the structures is different on
different MPI processes.
...
#define NUM_ELEMS 10
#define LLIST_ELEM_NEXT_RANK ( offsetof(llist_elem_t, next) + \
offsetof(llist_ptr_t, rank) )
#define LLIST_ELEM_NEXT_DISP ( offsetof(llist_elem_t, next) + \
offsetof(llist_ptr_t, disp) )
/* Linked list pointer */
typedef struct {
MPI_Aint disp;
int rank;
} llist_ptr_t;
/* Linked list element */
typedef struct {
llist_ptr_t next;
int value;
} llist_elem_t;
const llist_ptr_t nil = { (MPI_Aint) MPI_BOTTOM, -1 };
/* List of locally allocated list elements. */
static llist_elem_t **my_elems = NULL;
static int my_elems_size = 0;
static int my_elems_count = 0;
/* Allocate a new shared linked list element */
MPI_Aint alloc_elem(int value, MPI_Win win) {
MPI_Aint disp;
llist_elem_t *elem_ptr;
/* Allocate the new element and register it with the window */
MPI_Alloc_mem(sizeof(llist_elem_t), MPI_INFO_NULL, &elem_ptr);
elem_ptr->value = value;
elem_ptr->next = nil;
MPI_Win_attach(win, elem_ptr, sizeof(llist_elem_t));
/* Add the element to the list of local elements so we can free
it later. */
if (my_elems_size == my_elems_count) {
my_elems_size += 100;
my_elems = realloc(my_elems, my_elems_size*sizeof(void*));
}
my_elems[my_elems_count] = elem_ptr;
my_elems_count++;
MPI_Get_address(elem_ptr, &disp);
return disp;
}
int main(int argc, char *argv[]) {
int procid, nproc, i;
MPI_Win llist_win;
llist_ptr_t head_ptr, tail_ptr;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &procid);
MPI_Comm_size(MPI_COMM_WORLD, &nproc);
MPI_Win_create_dynamic(MPI_INFO_NULL, MPI_COMM_WORLD, &llist_win);
/* Process 0 creates the head node */
if (procid == 0)
head_ptr.disp = alloc_elem(-1, llist_win);
/* Broadcast the head pointer to everyone */
head_ptr.rank = 0;
MPI_Bcast(&head_ptr.disp, 1, MPI_AINT, 0, MPI_COMM_WORLD);
tail_ptr = head_ptr;
/* Lock the window for shared access to all targets */
MPI_Win_lock_all(0, llist_win);
/* All processes concurrently append NUM_ELEMS elements to the list */
for (i = 0; i < NUM_ELEMS; i++) {
llist_ptr_t new_elem_ptr;
int success;
/* Create a new list element and attach it to the window */
new_elem_ptr.rank = procid;
new_elem_ptr.disp = alloc_elem(procid, llist_win);
/* Append the new node to the list. This might take multiple
attempts if others have already appended and our tail pointer
is stale. */
do {
llist_ptr_t next_tail_ptr = nil;
MPI_Compare_and_swap((void*) &new_elem_ptr.rank, (void*) &nil.rank,
(void*)&next_tail_ptr.rank, MPI_INT, tail_ptr.rank,
MPI_Aint_add(tail_ptr.disp, LLIST_ELEM_NEXT_RANK),
llist_win);
MPI_Win_flush(tail_ptr.rank, llist_win);
success = (next_tail_ptr.rank == nil.rank);
if (success) {
MPI_Accumulate(&new_elem_ptr.disp, 1, MPI_AINT, tail_ptr.rank,
MPI_Aint_add(tail_ptr.disp, LLIST_ELEM_NEXT_DISP), 1,
MPI_AINT, MPI_REPLACE, llist_win);
MPI_Win_flush(tail_ptr.rank, llist_win);
tail_ptr = new_elem_ptr;
} else {
/* Tail pointer is stale, fetch the displacement. May take
multiple tries if it is being updated. */
do {
MPI_Get_accumulate(NULL, 0, MPI_AINT, &next_tail_ptr.disp,
1, MPI_AINT, tail_ptr.rank,
MPI_Aint_add(tail_ptr.disp, LLIST_ELEM_NEXT_DISP),
1, MPI_AINT, MPI_NO_OP, llist_win);
MPI_Win_flush(tail_ptr.rank, llist_win);
} while (next_tail_ptr.disp == nil.disp);
tail_ptr = next_tail_ptr;
}
} while (!success);
}
MPI_Win_unlock_all(llist_win);
MPI_Barrier(MPI_COMM_WORLD);
/* Free all the elements in the list */
for ( ; my_elems_count > 0; my_elems_count--) {
MPI_Win_detach(llist_win,my_elems[my_elems_count-1]);
MPI_Free_mem(my_elems[my_elems_count-1]);
}
MPI_Win_free(&llist_win);
...