MPI guarantees certain general properties of partitioned point-to-point communication progress, which are described in this section.
Persistent communications use opaque MPI_REQUEST objects as described in Section Point-to-Point Communication. Partitioned communication uses these same semantics for MPI_REQUEST objects.
Partitioned communication provides fine-grained transfers on either or both sides of a send-receive operation described by requests. Persistent communication semantics are ideal for partitioned communication: they provide MPI_PSEND_INIT and MPI_PRECV_INIT functions that allow partitioned communication setup to occur prior to message transfers. Partitioned communication initialization functions are local. The partitioned communication initialization includes inputs on the number of user-visible partitions on the send-side and receive-side, which may differ. Valid partitioned communication operations must have one or more partitions specified.
Once an MPI_PSEND_INIT call has been made, the user may start the operation with a call to a starting procedure and complete the operation with a number of MPI_PREADY calls equal to the requested number of send partitions followed by a call to a completing procedure. A call to MPI_PREADY notifies the MPI library that a specified portion of the data buffer (a specific partition) is ready to be sent. Notification of partial completion can be done via fine-grained MPI_PARRIVED calls at the receiver before a final MPI_TEST/ MPI_WAIT on the request itself; the latter represents overall operation completion upon success. A full set of methods for starting and completing partitioned communication is given in the following sections.
Advice to users.
Having a large number of receiver-side partitions can increase overheads as the completion mechanism may need to work with finer-grained notifications. Using a small number of receiver-side partitions may provide higher performance.
A large number of sender-side partitions may be aggregated by an MPI implementation,
making performance concerns of a large number of sender-side partitions potentially less impactful
than receiver-side granularity.
( End of advice to users.)
Advice
to implementors.
It is expected that an MPI implementation will attempt to balance
latency and aggregation for
data transfers for the requested partition counts on the sender-side and receiver-side
to allow optimization for different hardware. A high quality implementation may
perform significant optimizations to enhance performance in this way; they may, for example,
resize the data transfers of the partitions to combine partitions in fractional
partition sizes (e.g., 2.5 partitions in a single data transfer).
( End of advice to implementors.)
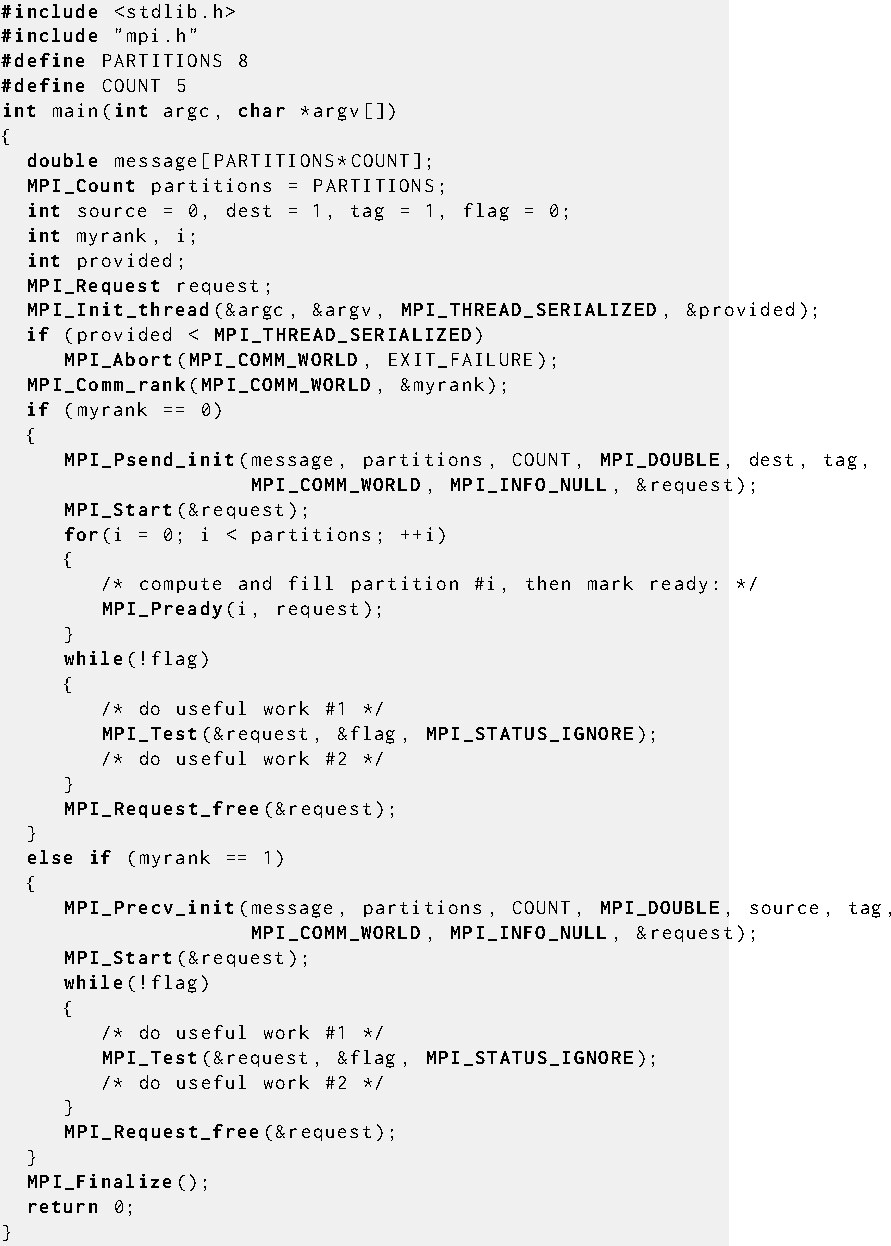
Example Semantics of Partitioned Point-to-Point Communication shows a simple partitioned transfer
in which the sender-side and receiver-side partitioning is identical in partition count.
Example
Simple partitioned communication example.
Rationale.
Partitioned communication is designed to provide opportunities for MPI implementations to
optimize data transfers. MPI is free to choose how many transfers to do within a partitioned communication send
independent of how many partitions are reported as ready to MPI through
MPI_PREADY calls.
Aggregation of partitions is permitted but not required. Ordering of partitions is permitted but not required.
A naive implementation can simply
wait for the entire message buffer to be marked ready before any transfer(s) occur and
could wait until the completion function is called on a request before transferring data.
However, this modality of communication gives MPI implementations far more flexibility in data
movement than
nonpartitioned communications.
( End of rationale.)