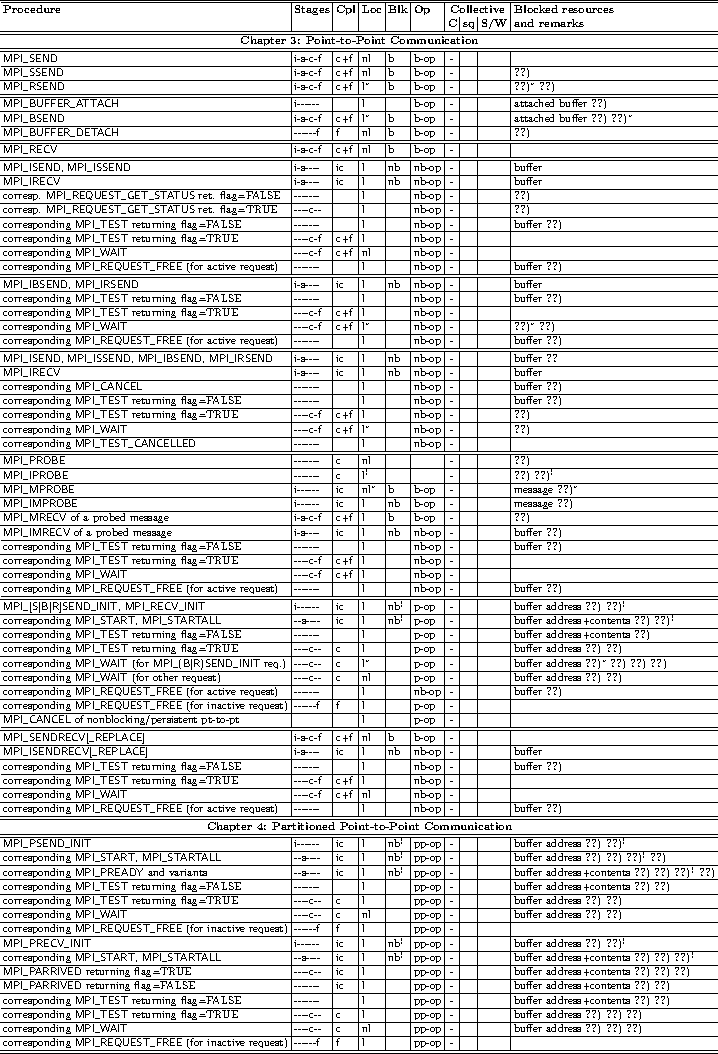
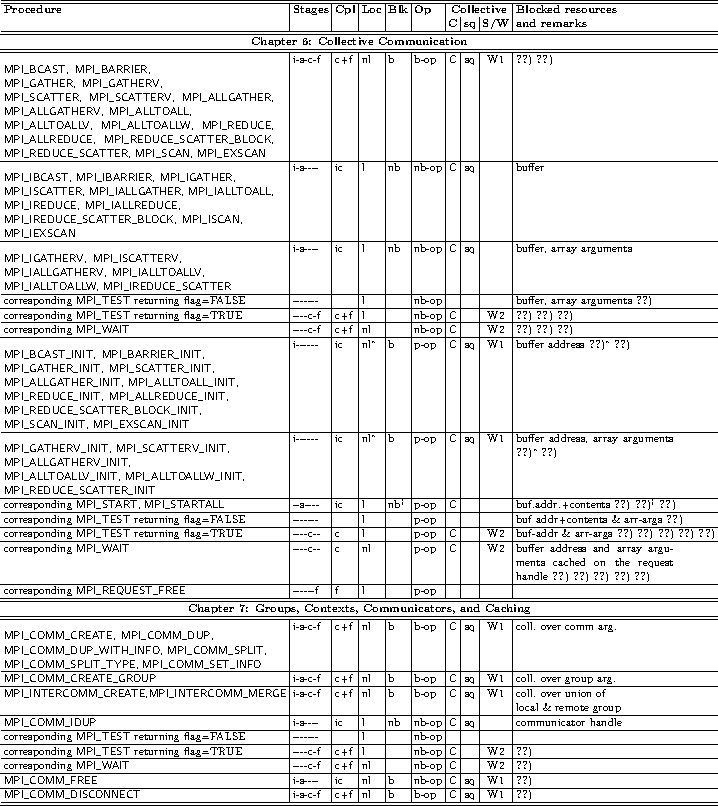
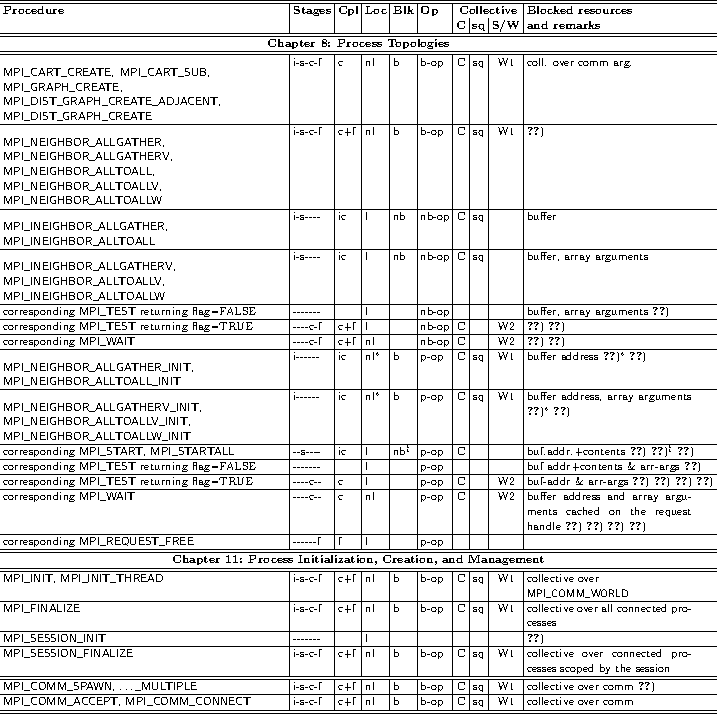
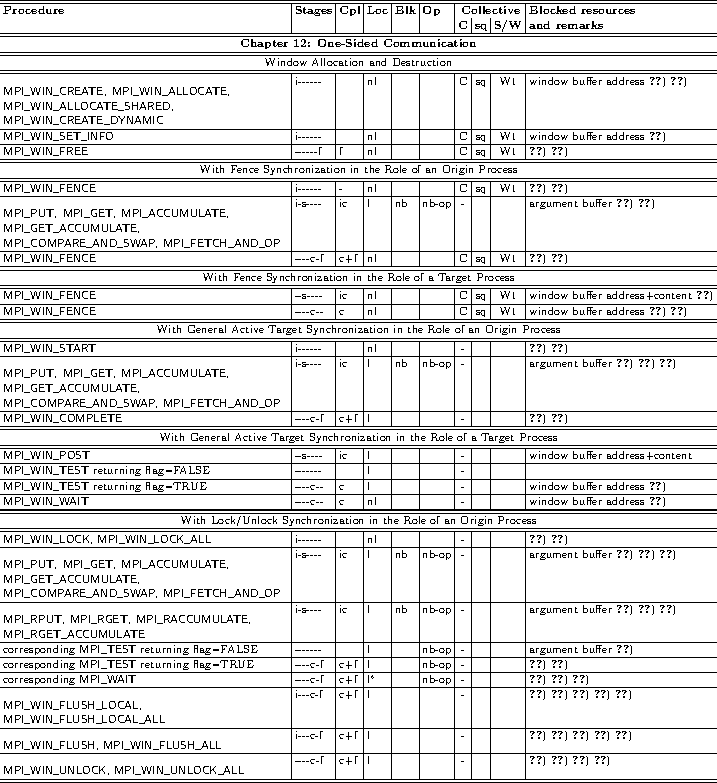
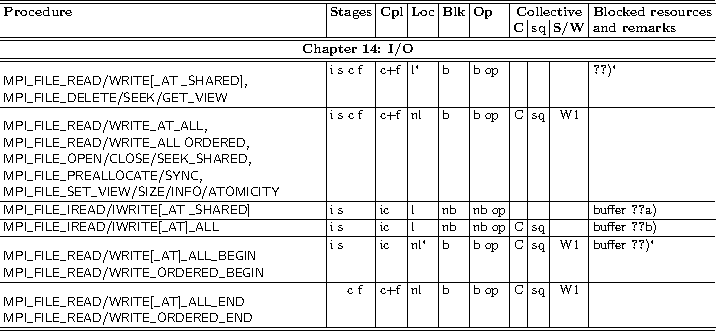
21.2. Summary of the Semantics of all Operation-Related MPI Procedures

Up: Language Bindings Summary
Next: C Bindings
Previous: Info Values
This annex
provides the list of MPI procedures that are associated with an MPI
operation, or inquiry procedures providing information about an operation.
In many cases, the MPI procedures and their properties are listed under certain constraints,
e.g., a call to MPI_WAIT that completes either a nonblocking or a persistent operation,
or RMA calls in combination with various synchronization methods.
Table Legend:
- Stages: i=initialization, s=starting, c=completion, f=freeing.
The procedure does at least part
of the indicated stage(s).
- Cpl: ic=incomplete procedure, c=completing procedure, f=freeing procedure
- Loc: l=local procedure, nl=non-local procedure
- *: exceptions, e.g., ic+nl = incomplete+non-local, and c+l = completing+local (both are defined as blocking)
- Blk: b=blocking procedure, nb=nonblocking procedure. Note that from a user's view point, this column is only a hint. Relevant is,
whether a routine is local or not and which resources are blocked until when. See both previous and last columns.
-
 : exceptions, e.g., nonblocking procedures without prefix I, or that prefix I only marks immediate return.
: exceptions, e.g., nonblocking procedures without prefix I, or that prefix I only marks immediate return.
- Op: part of operation type: b-op = blocking operation,
nb-op = nonblocking operation, p-op = persistent operation,
pp-op = persistent partitioned operation
- Collective procedures:
- C = all processes of the group must call the procedure
- sq = in the same sequence
- S1 = blocking synchronization, i.e., no process shall return from this procedure
until all processes on the associated process group called this procedure
- W1 = the implementation is permitted to do S1 but not required to do S1
- S2 = start-complete-synchronization, i.e., no process shall complete the associated operation
until all processes on the associated process group have called the associated starting procedure
- W2 = the implementation is permitted to do S2 but not required to do S2
- Blocked resources: They are blocked after the call until the end of the subsequent stage where this resource is not mentioned further in the table.
Table Remarks:
1. Must not return before the corresponding MPI receive operation is started.
2. Not related to an MPI operation.
Prior to MPI-4.0, MPI_PROBE and MPI_IPROBE
were also described as blocking and nonblocking.
From MPI-4.0 onwards, only non-local and local are used to describe these procedures.
3. Usually, MPI_WAIT is non-local, but in this case it is local.
4. In case of a MPI_(I)BARRIER on an intra-communicator,
the S1/S2 synchronization is required (instead of W1/W2).
5. Collective: all processes must complete, but with the free choice of using MPI_WAIT
or MPI_TEST returning flag = TRUE.
6. It also may not return until MPI_INIT was called in the children.
7. Addresses are cached on the request handle.
8.
One of the rare cases that an incomplete call is non-local and therefore blocking.
9. One shall not free or deallocate the buffer before the operation is freed, that is MPI_REQUEST_FREE returned.
10. For MPI_WAIT and MPI_TEST, see corresponding lines for a) MPI_BSEND, or b) MPI_IBCAST.
11.
The prefix I marks only that this procedure returns immediately.
12.
One of the exceptions that a completing and therefore blocking operation-related procedure is local.
13. MPI_(I)MPROBE
initializes the operation through generating the message handle
whereas
MPI_(I)MRECV
initializes the receive buffer
(i.e., two MPI procedures together implement the initialization stage).
14. Nonblocking procedure without an I prefix.
15. Initialization stage (`` i'') only if flag = TRUE is returned else no operation is progressed.
16. Collective: all processes must start, but with the free choice of using MPI_START
or MPI_STARTALL for a given persistent request handle
(i.e., if one process starts a persistent request handle then all processes
of the associated process group must start their corresponding request handle,
and if any process starts then all processes must complete their handles).
17. In a correct MPI program, a call to MPI_(I)RSEND requires
that the receiver has already started the corresponding receive.
Under this assumption, the call to MPI_RSEND and the call to
MPI_WAIT with an (active) ready send request handle are local.
18. Based on their semantics, when called using an intra-communicator, MPI_ALLGATHER,
MPI_ALLTOALL, and their V and W
variants, MPI_ALLREDUCE, MPI_REDUCE_SCATTER, and MPI_REDUCE_SCATTER_BLOCK
must synchronize (i.e., S1/S2 instead of W1/W2) provided that all counts
and the size of all datatypes are larger than zero.
19. MPI_COMM_FREE may return
before any pending communication has finished and the communicator
is deallocated. In contrast, MPI_COMM_DISCONNECT waits
for pending communicaton to finish and deallocates the
communicator before it returns.
20. The request handle is in the ``active'' state after MPI_START, i.e., MPI_REQUEST_FREE is now forbidden.
But the starting stage is not yet finished, and the contents of the buffer are not yet ``blocked.''
An additional MPI_PREADY and variants MPI_PREADY_RANGE MPI_PREADY_LIST
are required to activate each partition of the send buffer to finish the starting stage.
21. As part of the completion stage, the user is allowed to read part of the output buffer after returning
from MPI_PARRIVED with flag = TRUE before completing the whole operation with a MPI_WAIT/ MPI_TEST procedure.
22. It initializes the attached buffer as completely free.
23. It uses the attached buffer and performs all four stages on the send buffer. It occupies the needed part of the attached buffer.
24. It waits until the attached buffer is empty, i.e., all messages have been transmitted, and then releases the attached buffer.
25. Although in case of flag = TRUE the operation is completed,
a subsequent call to test, wait, or free must be executed for deallocating or inactivating
the request handle as final part of the stages c and f. It is listed only in this scenario,
but can be used everywhere, where MPI_TEST can be called.
26. It frees the request handle. If the related communication
operation is still ongoing then the completion and freeing stage can take place after the
procedure returned.
27. Cancelling a send request is deprecated.
28. Can also be applied to activ persistent requests.
29. As an exception, MPI_WAIT is local and
MPI_TEST repeatedly called will eventually return flag =true.
The cancelled send or receive operation is completed and the buffer can be reused. Whether the message is sent out from the buffer or received in the buffer, this part of the completion stage is only executed if a subsequent
MPI_TEST_CANCELLED for the returned status would
return flag = FALSE.
The freeing stage will be performed only for non-persistent requests.
30. In some cases, more than one MPI procedure may be
needed to implement one stage of an MPI one-sided operation.
For details on the semantics of one-sided operations, see Chapter One-Sided Communications.
31. Local completion only (at origin).
32. Local completion only (at target).
33. Completion at target and locally at origin.
34. Return from MPI_WIN_START and these
subsequent procedures at the origin process may be delayed until MPI_WIN_POST
has been called at the target process (see Section Synchronization Calls
and Example General Active Target Synchronization).
35. Return from MPI_WIN_LOCK and these
subsequent procedures may be delayed until other origin processes have released
their lock (see Section Synchronization Calls and Example Lock).
36. The init and freeing stages and the buffer address of
the target window only apply to MPI processes in the role of a target of an RMA operation.
37. The freeing stage applies to operations only
and does not apply to any request.
38. The same procedure call may serve different
stages for different operations, i.e.,
the completion of a previous RMA and/or exposure epoch and/or
the start of a next RMA and/or exposure epoch.
39. In addition to the completion and freeing of
the RMA operations prior the the flush call (stages `` c+f''),
this call initializes the next RMA epoch (stage `` i'').
40. The stages represent the invocation as part of an RMA operation.
As collective procedure itself, it is a blocking procedure with all stages.
Up: Language Bindings Summary
Next: C Bindings
Previous: Info Values
Return to MPI-4.1 Standard Index
Return to MPI Forum Home Page
(Unofficial) MPI-4.1 of November 2, 2023
HTML Generated on November 19, 2023