| MPI_WIN_START(group, assert, win) | |
| IN group | group of target processes (handle) |
| IN assert | program assertion (integer) |
| IN win | window object (handle) |
Opens an RMA access epoch for win. RMA calls issued on win during this epoch must access only windows at MPI processes in group. Each MPI process in group must issue a matching call to MPI_WIN_POST. RMA accesses to each target window will be delayed, if necessary, until the target process executed the matching call to MPI_WIN_POST. MPI_WIN_START is allowed to delay its return until the corresponding calls to MPI_WIN_POST have occurred, but is not required to.
The assert argument is used to provide assertions on the context of the call that may be used for various optimizations. This is described in Section Assertions. A value of assert = 0 is always valid.
| MPI_WIN_COMPLETE(win) | |
| IN win | window object (handle) |
Closes an RMA access epoch on win opened by a call to MPI_WIN_START. All RMA communication operations initiated on win during this epoch will have completed at the origin when the call returns. All updates to shared memory in win through load/store accesses executed during this epoch will be visible at the target when the call returns.
MPI_WIN_COMPLETE enforces completion of preceding RMA operations and visibility of load/store accesses at the origin, but not at the target. A put or accumulate operation may not have completed at the target when it has completed at the origin.
Consider the sequence of calls in the example below.
Example
Use of MPI_WIN_START and MPI_WIN_COMPLETE.

The call to MPI_WIN_COMPLETE does not return until the put operation has completed at the origin; and the target window will be accessed by the put operation only after the call to MPI_WIN_START has matched a call to MPI_WIN_POST by the target process.
Advice
to implementors.
The semantics described above still leave
much choice to implementors. The return from the call to
MPI_WIN_START can block until the matching call to
MPI_WIN_POST occurs at all target processes. One can also
have implementations where the call to MPI_WIN_START returns immediately, but the
call to MPI_WIN_COMPLETE delays its return until the call to
MPI_WIN_POST occurred; or implementations where all
three calls can complete before any target process
has called
MPI_WIN_POST---the
data put must be buffered, in this last case, so as to allow the
put to complete at the origin ahead of its completion at the
target.
However, once the
call to MPI_WIN_POST is issued, the sequence above
must complete, without further dependencies.
( End of advice to implementors.)
Advice to users.
In order to ensure a portable deadlock free program, users must assume that
MPI_WIN_START may delay its return until the corresponding call
to MPI_WIN_POST has occurred.
( End of advice to users.)
| MPI_WIN_POST(group, assert, win) | |
| IN group | group of origin processes (handle) |
| IN assert | program assertion (integer) |
| IN win | window object (handle) |
Opens an RMA exposure epoch for the local window associated with win. Only MPI processes in group may access the window with RMA calls on win during this epoch. Each MPI process in group must issue a matching call to MPI_WIN_START. MPI_WIN_POST is a local procedure.
| MPI_WIN_WAIT(win) | |
| IN win | window object (handle) |
Closes an RMA exposure epoch opened by a call to MPI_WIN_POST on win. This call matches calls to MPI_WIN_COMPLETE on win issued by each of the origin processes that were granted access to the window during this epoch. The call to MPI_WIN_WAIT will return only after all matching calls to MPI_WIN_COMPLETE have occurred. This guarantees that all these origin processes have completed their RMA operations and shared-memory load/store accesses have become visible on the local window. When the call returns, all these RMA accesses will have completed at the target window.
Figure 31 illustrates the use of these four functions.
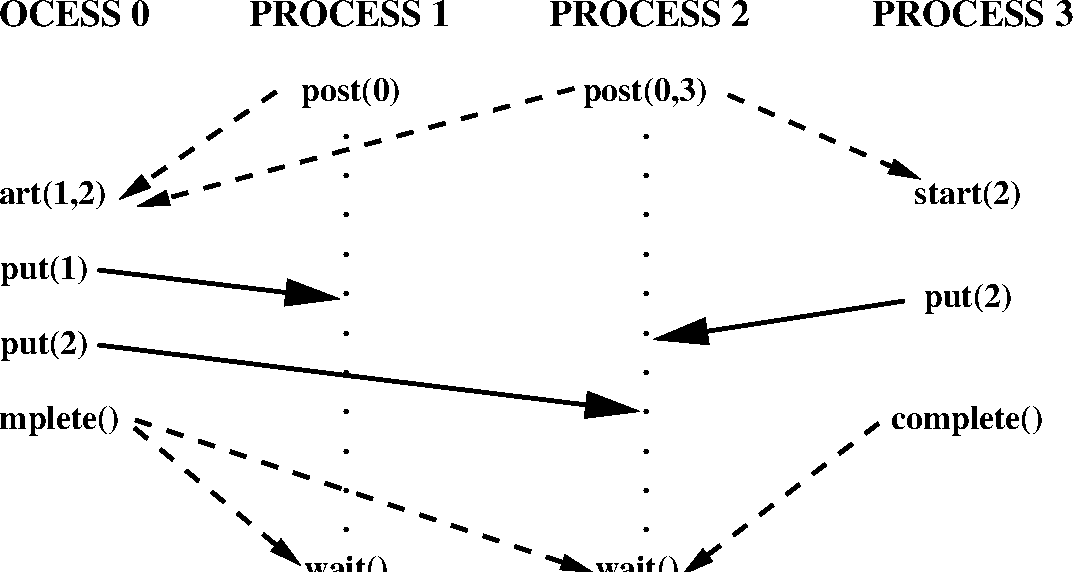
Process 0 puts data in the windows of processes 1 and 2 and process 3 puts data in the window of process 2. Each start call lists the ranks of the MPI processes whose windows will be accessed; each post call lists the ranks of the MPI processes that access the local window. The figure illustrates a possible timing for the events, assuming strong synchronization; in a weak synchronization, the start, put or complete calls may occur ahead of the matching post calls.
| MPI_WIN_TEST(win, flag) | |
| IN win | window object (handle) |
| OUT flag | success flag (logical) |
MPI_WIN_TEST is a local procedure. Repeated calls to MPI_WIN_TEST with the same win argument will eventually return flag = true once all accesses to the local window by the group to which it was exposed by the corresponding call to MPI_WIN_POST have been completed as indicated by matching MPI_WIN_COMPLETE calls, and flag = false otherwise. In the former case MPI_WIN_WAIT would have returned immediately. The effect of return of MPI_WIN_TEST with flag = true is the same as the effect of a return of MPI_WIN_WAIT. If flag = false is returned, then the call has no visible effect.
MPI_WIN_TEST should be called only where MPI_WIN_WAIT can be called. Once the call has returned flag = true, it must not be called again, until the window is posted again.
Assume that window win is associated with a ``hidden'' communicator wincomm, used for communication by the MPI processes in the group of win. The rules for matching of post and start calls and for matching complete and wait calls can be derived from the rules for matching sends and receives, by considering the following (partial) model implementation.
Rationale.
The design for general active target synchronization requires the
user to provide complete information on the communication pattern, at
each end of a communication link: each origin specifies a list of
targets, and each target specifies a list of origins. This provides
maximum flexibility (hence, efficiency) for the implementor:
each
synchronization can be initiated by either side, since each ``knows''
the identity of the other. This also provides maximum protection from
possible races. On the other hand, the design requires more
information than RMA needs: in general, it is sufficient
for the origin to know the rank of the target, but not vice
versa.
Users that want more ``anonymous'' communication will be required to
use the fence or lock mechanisms.
( End of rationale.)
Advice to users.
Assume a communication pattern that is represented by a directed graph
![]() , where V = {0, ..., n-1} and
, where V = {0, ..., n-1} and ![]() if origin process
i accesses the window at target process j. Then each MPI process i
issues a call to
MPI_WIN_POST(ingroupi, ...),
followed by a call to
MPI_WIN_START(outgroupi,...),
where
if origin process
i accesses the window at target process j. Then each MPI process i
issues a call to
MPI_WIN_POST(ingroupi, ...),
followed by a call to
MPI_WIN_START(outgroupi,...),
where
![]() and
and ![]() . A call is a noop, and can be skipped, if the group argument is
empty. After the communications calls, each MPI process that issued
a start will issue a complete. Finally, each MPI process that
issued a post will issue a wait.
. A call is a noop, and can be skipped, if the group argument is
empty. After the communications calls, each MPI process that issued
a start will issue a complete. Finally, each MPI process that
issued a post will issue a wait.
Note that each MPI process may call with a group argument that has
different members.
( End of advice to users.)