The memory semantics of RMA are best understood by using the concept of public and private window copies. We assume that systems have a public memory region that is addressable by all MPI processes (e.g., the shared memory in shared memory machines or the exposed main memory in distributed memory machines). In addition, most machines have fast private buffers (e.g., transparent caches or explicit communication buffers) local to each MPI process where copies of data elements from the main memory can be stored for faster access. Such buffers are either coherent, i.e., all updates to main memory are reflected in all private copies consistently, or noncoherent, i.e., conflicting accesses to main memory need to be synchronized and updated in all private copies explicitly. Coherent systems allow direct updates to remote memory without any participation of the remote side. Noncoherent systems, however, need to call RMA functions in order to reflect updates to the public window in their private memory. Thus, in coherent memory, the public and the private window are identical while they remain logically separate in the noncoherent case. MPI thus differentiates between two memory models called RMA unified, if public and private window are logically identical, and RMA separate, otherwise.
In the RMA separate model, there is only one instance of each variable in MPI process memory, but a distinct public copy of the variable for each window that contains it. A load accesses the instance in MPI process memory (this includes MPI sends). A local store accesses and updates the instance in MPI process memory (this includes MPI receives), but the update may affect other public copies of the same locations. A get on a window accesses the public copy of that window. A put or accumulate on a window accesses and updates the public copy of that window, but the update may affect the private copy of the same locations in MPI process memory, and public copies of other overlapping windows. This is illustrated in Figure 27.
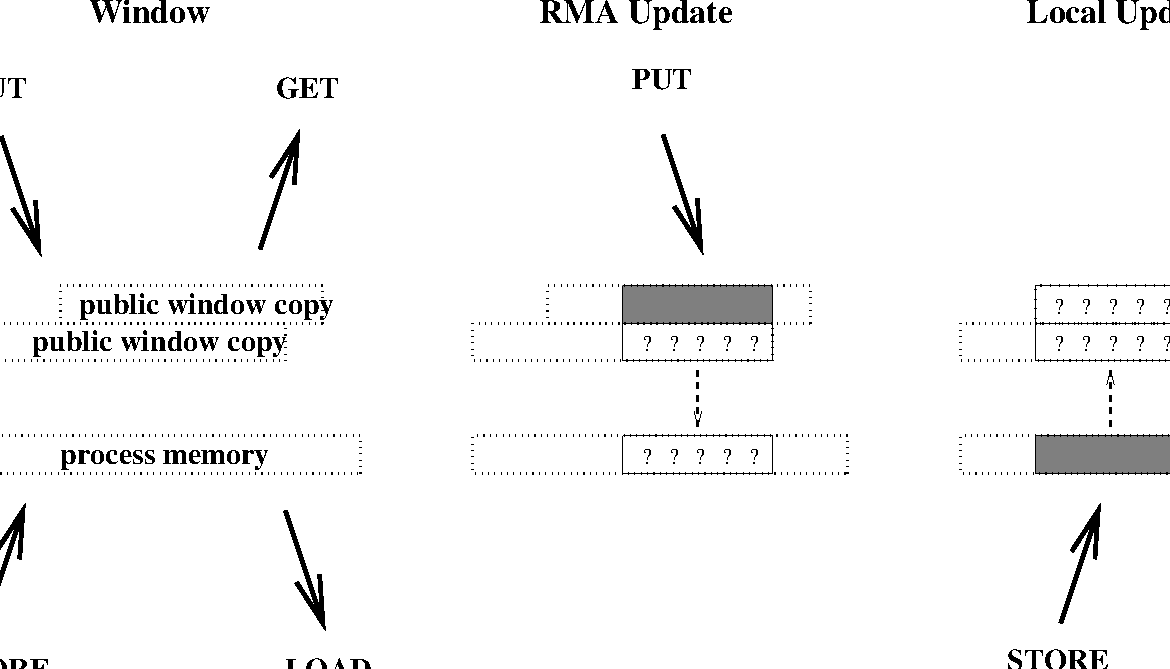
In the RMA unified model, public and private copies are identical and updates via put or accumulate operations are eventually observed by load accesses without additional RMA procedure calls. A store access to a window is eventually visible to remote get or accumulate operations without additional RMA procedure calls. These stronger semantics of the RMA unified model allow the user to omit some synchronization calls and potentially improve performance.
Advice to users.
If accesses in the RMA unified model are not synchronized (with locks or
flushes, see Section Lock), load/store accesses
might observe changes to the memory while they are in progress. The
order in which data is written is not specified unless further
synchronization is used. This might lead to inconsistent views on
memory and programs that assume that a transfer is complete by only
checking parts of the message are erroneous.
( End of advice to users.)
The memory model for a particular RMA window can be determined by
accessing the attribute MPI_WIN_MODEL. If the memory model
is the unified model, the value of this attribute is
MPI_WIN_UNIFIED; otherwise, the value is
MPI_WIN_SEPARATE.