![]()
C binding
int MPI_Finalize(void)
Fortran 2008 binding
MPI_Finalize(ierror)
INTEGER, OPTIONAL, INTENT(OUT) :: ierror
Fortran binding
MPI_FINALIZE(IERROR)
INTEGER IERROR
This routine cleans up all MPI state associated with the World Model. If an MPI program that initializes the World Model terminates normally (i.e., not due to a call to MPI_ABORT or an unrecoverable error) then each process must call MPI_FINALIZE before it exits.
Before an MPI process invokes MPI_FINALIZE, the process must perform all MPI calls needed to complete its involvement in MPI communications associated with the World Model. It must locally complete all MPI operations that it initiated and must execute matching calls needed to complete MPI communications initiated by other processes. For example, if the process executed a nonblocking send, it must eventually call MPI_WAIT, MPI_TEST, MPI_REQUEST_FREE, or any derived function; if the process is the target of a send, then it must post the matching receive; if it is part of a group executing a collective operation, then it must have completed its participation in the operation. This means that before calling MPI_FINALIZE, all message handles associated with the World Model must be received (with MPI_MRECV or derived procedures) and all request handles associated with the World Model must be freed in the case of nonblocking operations, and must be inactive or freed in the case of persistent operations (i.e., by calling one of the procedures MPI_{TEST|WAIT}{|ANY|SOME|ALL} or MPI_REQUEST_FREE).
The call to MPI_FINALIZE does not clean up MPI state associated with objects created using MPI_SESSION_INIT and other Sessions Model methods, nor objects created using the communicator returned by MPI_COMM_GET_PARENT. See Sections The Sessions Model and Process Manager Interface.
The call to MPI_FINALIZE does not free objects created by MPI calls; these objects are freed using MPI_ XXX_FREE, MPI_COMM_DISCONNECT, or MPI_FILE_CLOSE calls.
Once MPI_FINALIZE returns, no MPI procedure may be called in the World Model (not even MPI_INIT, or freeing objects created within the World Model), except for those listed in Section MPI Functionality that is Always Available.
MPI_FINALIZE is collective over all connected processes. If no processes were spawned, accepted or connected then this means over MPI_COMM_WORLD; otherwise it is collective over the union of all processes that have been and continue to be connected, as explained in Section Releasing Connections.
The following examples illustrate these rules.
Example
The following code is correct

Example
Without a matching receive, the program is erroneous

Example
This program is correct: Process 0 calls
MPI_Finalize after it has executed
the MPI calls that complete the
send operation. Likewise, process 1 executes the MPI call
that completes the matching receive operation before it calls MPI_Finalize.

Example
This program is correct. The attached buffer is a resource
allocated by the user, not by MPI; it is available to the user
after MPI is finalized.

Example
This program is correct. The cancel operation must succeed,
since the send cannot complete normally. The wait operation, after
the call to MPI_Cancel, is
local---no matching MPI call is required on process 1.
Cancelling a send request by calling MPI_CANCEL is deprecated.
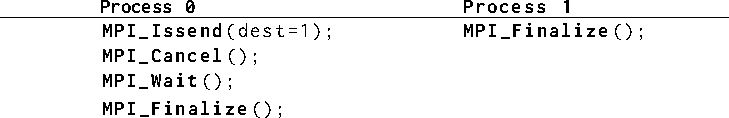
Advice
to implementors.
Even though a process has
executed all MPI calls needed to complete the communications
it is involved with, such
communication may not yet be completed from the viewpoint of the underlying
MPI system. For example, a blocking send may have returned, even though the data
is still buffered
at the sender in an MPI
buffer; an MPI process may receive a cancel request for a
message it has completed receiving. The MPI implementation must ensure that a
process has completed any involvement in MPI communication before
MPI_FINALIZE returns. Thus, if a process exits after the call to
MPI_FINALIZE, this will not cause an ongoing communication to
fail.
The MPI implementation should also complete freeing all
objects marked for deletion by MPI calls that freed them.
See also Section Progress on progress.
( End of advice to implementors.)
Failures may disrupt MPI operations during and after MPI finalization.
A high quality implementation shall not deadlock in MPI finalization, even in
the presence of failures. The normal
rules for MPI error handling continue to apply.
After MPI_COMM_SELF has been ``freed'' (see Section Allowing User Functions at MPI Finalization), errors that are not associated
with a communicator, window, or file raise the initial error handler (set during the launch operation, see Reserved Keys).
Although it is not required that all processes return from MPI_FINALIZE, it is required that, when it has not failed or aborted, at least the MPI process that was assigned rank 0 in MPI_COMM_WORLD returns, so that users can know that the MPI portion of the computation is over. In addition, in a POSIX environment, users may desire to supply an exit code for each process that returns from MPI_FINALIZE.
Note that a failure may terminate the MPI process that was assigned rank 0 in MPI_COMM_WORLD, in which case it is possible that no MPI process returns from MPI_FINALIZE.
Advice to users.
Applications that handle errors are encouraged to implement all rank-specific
code before the call to MPI_FINALIZE. In Example Finalizing MPI,
the process with rank 0 in MPI_COMM_WORLD may have been terminated before,
during, or after the call to MPI_FINALIZE, possibly leading to the code
after MPI_FINALIZE never being executed.
( End of advice to users.)
Example
The following illustrates the use of requiring that at least one
process return and that it be known that process 0 is one of the processes
that return. One wants code like the following to work no matter how many
processes return.
