One-sided communication has the same progress requirements as point-to-point communication: once a communication is enabled, then it is guaranteed to complete. RMA calls must have local semantics, except when required for synchronization with other RMA calls.
There is some fuzziness in the definition of the time when a RMA communication becomes enabled. This fuzziness provides to the implementor more flexibility than with point-to-point communication. Access to a target window becomes enabled once the corresponding synchronization (such as MPI_WIN_FENCE or MPI_WIN_POST) has executed. On the origin process, an RMA communication may become enabled as soon as the corresponding put, get or accumulate call has executed, or as late as when the ensuing synchronization call is issued. Once the communication is enabled both at the origin and at the target, the communication must complete.
Consider the code fragment in Example General Active Target Synchronization , on page General Active Target Synchronization . Some of the calls may block if the target window is not posted. However, if the target window is posted, then the code fragment must complete. The data transfer may start as soon as the put call occur, but may be delayed until the ensuing complete call occurs.
Consider the code fragment in Example Lock , on page Lock . Some of the calls may block if another process holds a conflicting lock. However, if no conflicting lock is held, then the code fragment must complete.
Consider the code illustrated in Figure 22 .
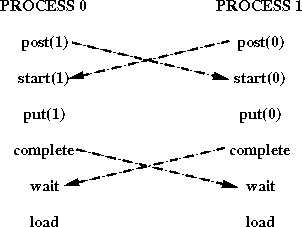
Each process updates the window of the other process using a put operation, then accesses its own window. The post calls are nonblocking, and should complete. Once the post calls occur, RMA access to the windows is enabled, so that each process should complete the sequence of calls start-put-complete. Once these are done, the wait calls should complete at both processes. Thus, this communication should not deadlock, irrespective of the amount of data transferred.
Assume, in the last example, that the order of the post and start calls is reversed, at each process. Then, the code may deadlock, as each process may block on the start call, waiting for the matching post to occur. Similarly, the program will deadlock, if the order of the complete and wait calls is reversed, at each process.
The following two examples illustrate the fact that the synchronization between complete and wait is not symmetric: the wait call blocks until the complete executes, but not vice-versa. Consider the code illustrated in Figure 23 .
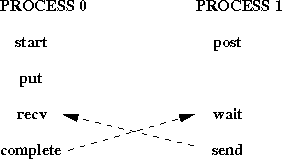
Figure 23: Deadlock situation
This code will deadlock: the wait of process 1 blocks until process 0 calls complete, and the receive of process 0 blocks until process 1 calls send. Consider, on the other hand, the code illustrated in Figure 24 .
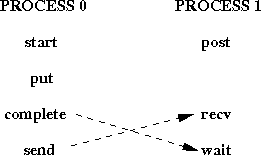
Figure 24: No deadlock
This code will not deadlock. Once process 1 calls post, then the sequence start, put, complete on process 0 can proceed to completion. Process 0 will reach the send call, allowing the receive call of process 1 to complete.
Rationale.
MPI implementations must guarantee that a process makes progress on all enabled communications it participates in, while blocked on an MPI call. This is true for send-receive communication and applies to RMA communication as well. Thus, in the example in Figure 24 , the put and complete calls of process 0 should complete while process 1 is blocked on the receive call. This may require the involvement of process 1, e.g., to transfer the data put, while it is blocked on the receive call.
A similar issue is whether such progress must occur
while a process is busy computing, or blocked in a
non- MPI call. Suppose that in the last example the send-receive
pair is replaced by a write-to-socket/read-from-socket pair. Then
MPI does not specify whether deadlock is avoided.
Suppose that the blocking
receive of process 1 is replaced by a very long compute loop. Then,
according to one interpretation of
the MPI standard, process 0 must return from the complete call after
a bounded delay, even if process 1 does not reach any MPI call in
this period of time. According to another interpretation, the
complete call may block until process 1 reaches the wait call, or
reaches another MPI call. The qualitative behavior is the same,
under both interpretations, unless a process is caught in an infinite compute loop, in which case the difference may not matter.
However, the quantitative expectations are different.
Different MPI implementations reflect these different
interpretations. While this ambiguity is unfortunate, it does not
seem to affect many real codes. The MPI forum
decided not to decide which interpretation of the standard is the
correct one, since the issue is very contentious, and a decision would
have much impact on implementors but less impact on users.
( End of rationale.)